Hacker Noon leaks drafts: what about your blog?

Does your CMS leak drafts?
I don’t know about you but I’d be pretty concerned if I found out an unfinished work or report I was working on, was visible to the public.
It is a common feature of blogging platforms to let authors “export” drafts that can be shared with friends and peers to seek feedback.
Ideally, these would need the viewer to sign-in to the website, but not always.
Medium, dev.to, and other sites have similar features which let you “preview” and share draft versions of your blog posts.
But in the case of Hacker Noon, I came across an interesting finding.
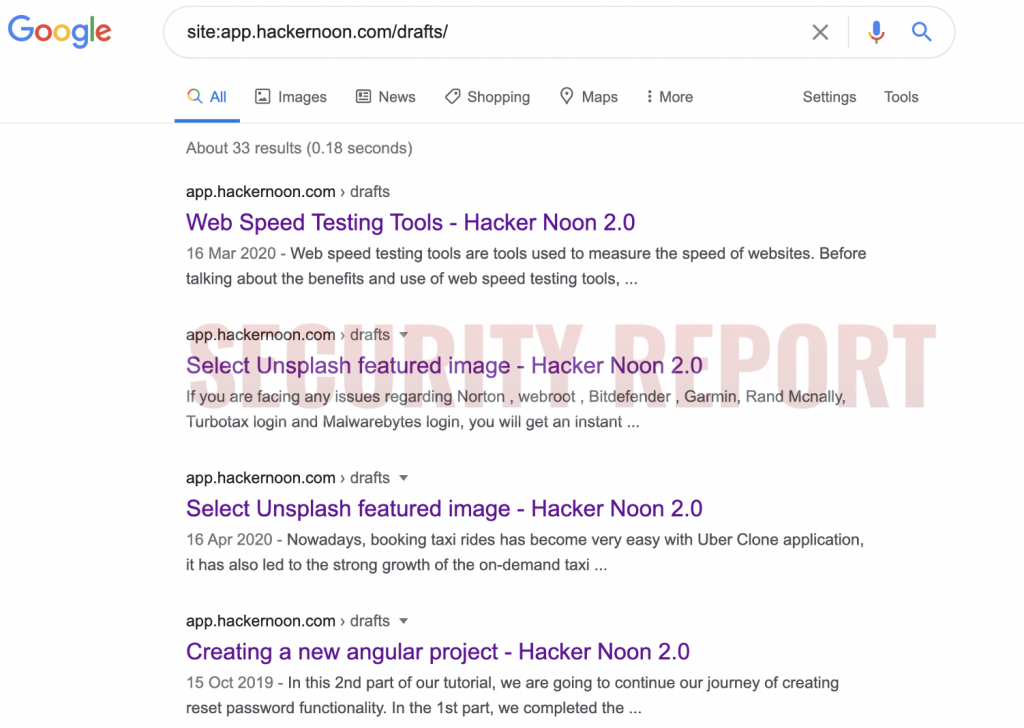
Google is indexing these unpublished drafts and it is not clear why.
Source: SecurityReport.com
Moreover, unlike with Medium or dev.to, because of Hacker Noon’s predictable URL structure of drafts, anyone can simply run a search with the following string to see these:
site:app.hackernoon.com/drafts/
This shows various kinds of unfinished pieces which are still in progress, being edited live, were submitted, or rejected at some point.
Indexed from public forums?
My first hunch was, perhaps, these drafts are being indexed by Google from public forums.
It isn’t uncommon for Hacker Noon authors to publicly post their finished draft links in community forums.
Typically authors do this to request editors to publish their drafts that have been sitting in the editorial queue for a while.
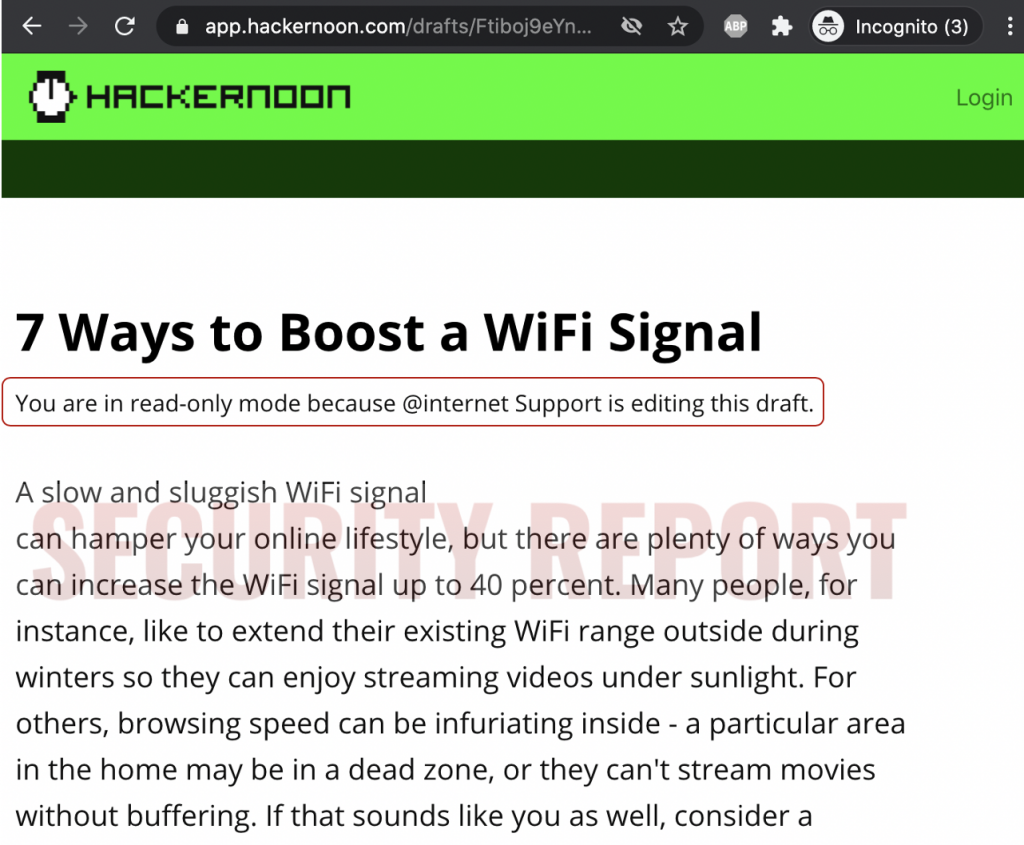
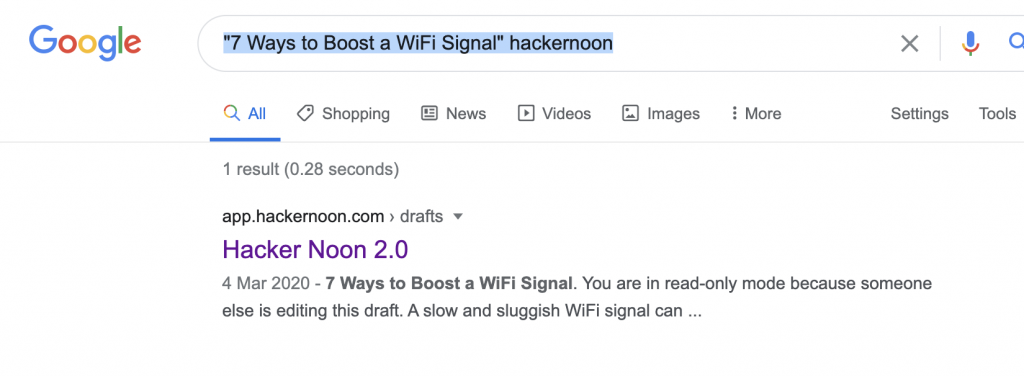
But in case of this particular article, for example, doing a search for its content yielded the one and only result: the unfinished draft.
Further to my investigation, there’s no “robots.txt” file on the “app.hackernoon.com” subdomain which could potentially prevent this by simply telling search engines not to look beyond “/drafts/.”
The “robots.txt” existing on the main hackernoon.com domain doesn’t (and can’t) do much in preventing the automatic indexing.
Finished pieces have ‘draft’ versions too
I have also seen “draft” clones of already published, live stories too.
For example, this published article can be accessed at its live link but also has its draft version available via search engines.
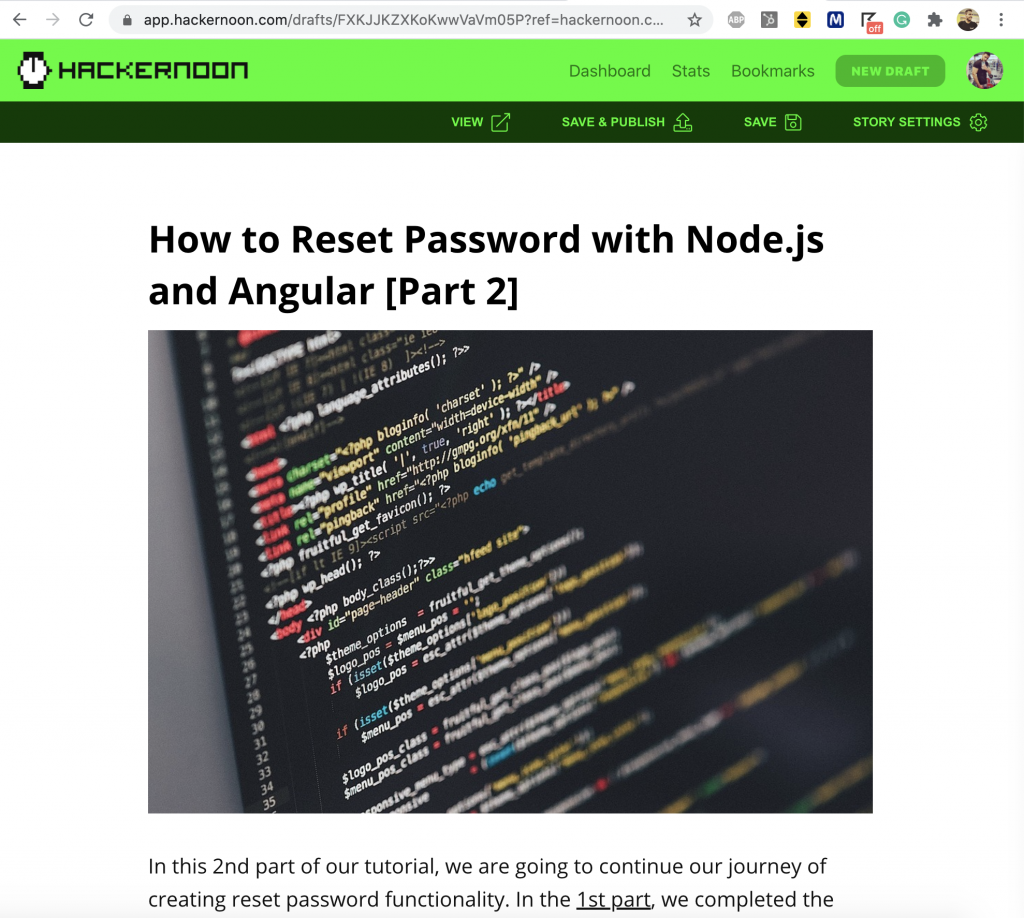
Thankfully, I was not able to overwrite any drafts. Altering the content and pressing “Save” or “Save and Publish” buttons would simply not bring about any updates—unless done by the rightful author of the story.
But the issue remains, why can I see unpublished drafts through Google?
And if the issue is with Hacker Noon, a popular “independent technology media site with 7,000+ contributing writers, 200,000+ daily readers and 8,000,000+ monthly pageviews,” how many other blogs may be impacted by flaws like these?
In the meantime, you may only want to put in Hacker Noon drafts what you’re okay with the world seeing.
Perhaps, use an offline word processor, and copy-paste your final content into Hacker Noon drafts just when you’re ready to submit.
Disclosure note: I had reported this issue to the Hacker Noon team last week via both email and Twitter but haven’t heard back since. Given this is a low severity flaw (most drafts wouldn’t reveal anything overly sensitive) and that Google already shows up the drafts, I have disclosed this flaw here.
Update Aug-13-2020: Hacker Noon has fixed the issue and a reply via a tweet provided more information:
“URL removal request went through https://google.com/search?q=site%3Aapp.hackernoon.com%2Fdrafts%2F… . all the pages on http://app.hackernoon.com had a `<meta name=”robots” content=”noindex, nofollow” />` tag, which has been updated content=”none” per https://developers.google.com/search/reference/robots_meta_tag#none“
© 2020. Ax Sharma. All Rights Reserved. Written for Security Report.


